Я держу небольшую инфраструктуру: 5 VPS, MySQL и ClickHouse кластеры. На них работают пет-проекты и небольшие продукты вроде VkAdsTool и ClearTranscriptBot. Есть реальные пользователи, которым важна стабильность.
Сервисы редко падают мгновенно. Обычно они сначала деградируют: начинают свопиться под нагрузкой, RAM Usage постепенно растёт на несколько мегабайт в час, из-за шумного соседа на общем хосте i/o latency может вырасти вплоть до 500 мс. Но к моменту, когда приходит алерт "сервис недоступен", инцидент уже влияет на пользователей.
Я использую Netdata на своих серверах достаточно давно, и не один раз она помогала увидеть признаки деградации до того, как становилось поздно. В статье расскажу, как её использую: установка, конфиги, алерты, как смотреть метрики всех серверов в одном месте и три реальных случая, в которых Netdata спасла меня от даунтайма.
Что я хочу от мониторинга
От мониторинга мне нужно одно: когда в 3 ночи что-то сломалось, за пять минут понять, что именно деградировало и с какого момента. Дальше уже разберусь, но эти пять минут критичные.
Для этого мне нужны метрики по:
- CPU по ядрам, отдельно system / user / iowait.
- Давление на память, swap-in / swap-out.
- Диск: throughput, IOPS, длина очереди, ошибки.
- Сеть: throughput, retransmits, packet drops.
- Здоровье сервисов: nginx, Postgres, MySQL, Redis, Docker, systemd-юниты.
- Алерты, которые помогают вовремя заметить проблему, а не десятки дашбордов, на которые редко смотрю.
Почему именно Netdata
Обычно для такого ставят Prometheus + Grafana. Но в моей инфраструктуре Netdata оказалась удобнее из-за другого набора компромиссов:
- Установка одной командой.
kickstart.sh— и через несколько минут агент уже собирает базовые метрики сервера. - Небольшое потребление ресурсов. Netdata остаётся достаточно лёгким агентом: у меня ест около 50-100 МБ RAM и 1-5% CPU.
- Метрики с разрешением в 1 секунду. При агрегации метрик с интервалом 10–30 секунд короткий 4-секундный спайк легко теряется в усреднении. С 1-секундным разрешением Netdata он остаётся видимым.
- Автоматическое обнаружение локальных сервисов. Если Nginx, Postgres, Redis, Docker или systemd находятся на той же машине, где установлен Netdata agent, метрики часто появляются автоматически после перезапуска агента.
- Алерты из коробки. Базовые алерты на CPU, RAM, disk, swap, load average и другие типичные проблемы уже настроены. Дальше остаётся адаптировать пороги под свою инфраструктуру.
Когда Netdata поймала то, что стало бы инцидентом
Ниже — три конкретные истории. Это не те проблемы, которые хорошо видны по healthcheck'у. Когда индикатор "сервис доступен" становится красным, пользователи уже сталкиваются с последствиями.
Случай 1. Утечка памяти, которая копилась неделю
Предыстория. В какой-то момент получаю сообщение от клиента, что сервис не работает. Быстро захожу по SSH, не нахожу процесса сервиса, смотрю в journalctl и вижу неприятные OOM Killed. Быстро перезапускаю и иду смотреть в код, чтобы найти проблему.
Неверное предположение. Конечно, я не хотел долго копаться в старом коде, поэтому просто предположил, что пользователь залил в сервис очень большой файл (который полностью загружается в RAM), для которого не хватало памяти. Поэтому просто поставил лимит на размер загружаемого файла.
Помогло ли это. Конечно нет! Это наоборот ухудшило ситуацию: я стал меньше смотреть за uptime сервиса, предполагая, что теперь точно не будет никакой ошибки.
Чем всё закончилось. После очередного падения я нашел банальную проблему в python-коде - сохранял данные в массив, но не удалял их. Если бы я использовал Netdata, то сразу бы заметил медленный, но постоянный рост RAM Usage.
Случай 2. Шумный сосед на общем диске
Преамбула. Простой бекенд на VPS начал тормозить в произвольные моменты. Ошибок никаких нет, ни в логах, ни в системных сообщениях.
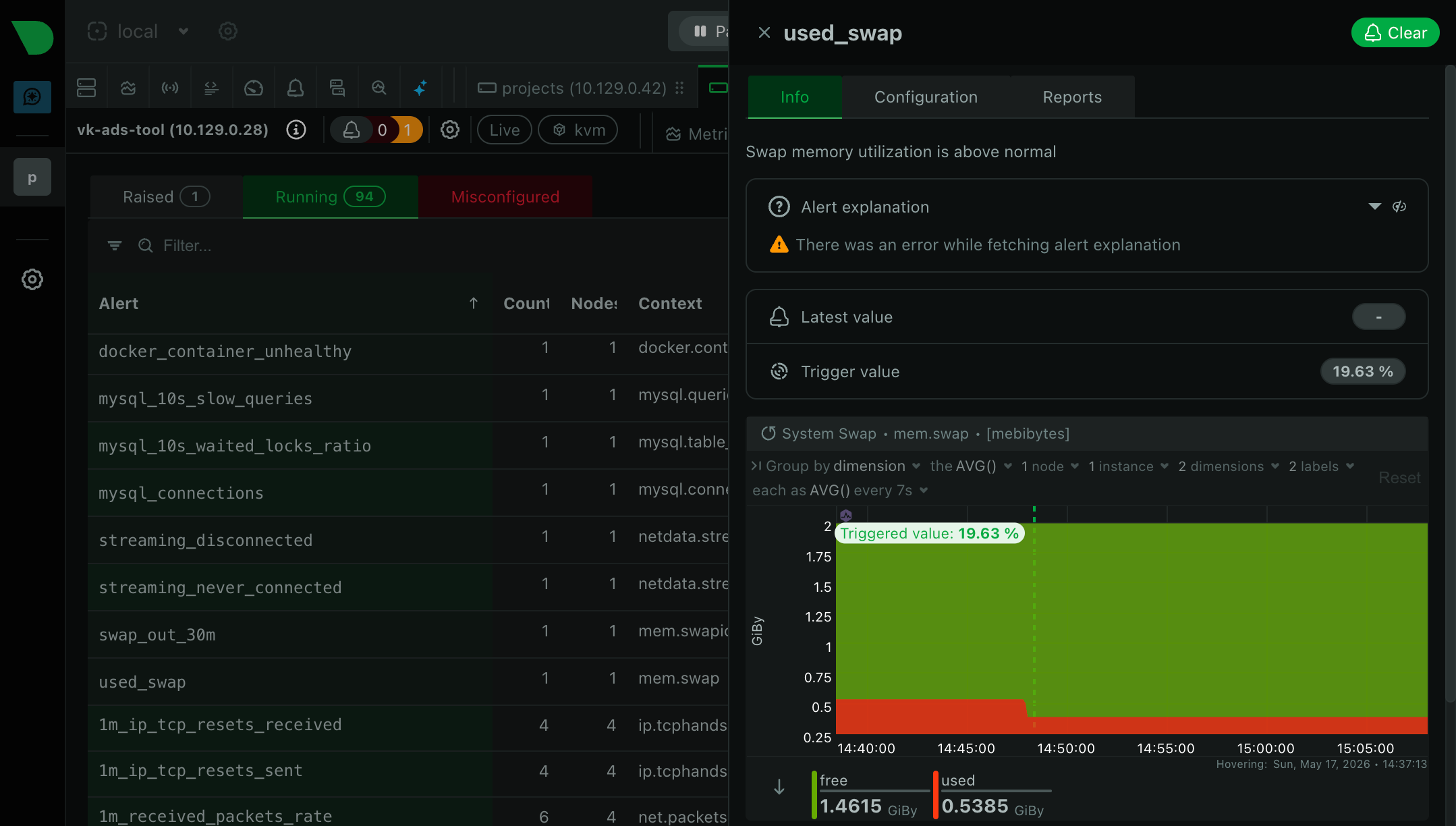
Что увидел в Netdata. В отличие от прошлых историй (когда у меня еще не было дашборда с метриками) я сразу же увидел, что disk.iops и disk.await улетели в космос, но собственный disk.io виртуалки оставался небольшим. Похоже, проблема была не в моем сервисе, а в шумном соседе на shared-хосте, который нагружал общий диск.
Что помогло. Написал в поддержку, и они перенесли мой сервис на другой хост. Плюс поправил настройки i/o алертов (каюсь, я их просто выключил).
Случай 3. Постепенный рост swap usage
С чего все началось. Бэкенд посложнее начал отдавать случайные 500-е. Latency-дашборд показывал повышенный p95 без явной причины. Свободного CPU было еще много. Первый инстинкт был простой: перезапустить сервис и посмотреть, повторится ли. Но это как раз тот случай, когда рестарт замаскировал бы причину.
Что показала Netdata. На графике mem.swapio увидел, что последние 36 часов постепенно увеличивался swap-out. Свободной памяти почти не оставалось. CPU выглядел нормально, но на самом деле процессор часто ждал диск: система тратила время не на полезную работу, а на постоянный обмен страницами памяти со swap.
Решение. В предыдущем обновлении конфига сервиса один из параметров был увеличен в 5 раз, но запаса по памяти на сервере уже не было. Даже небольшие дополнительные аллокации начали уходить в swap. Откатил конфиг и добавил два алерта: на system.ram available_percent < 15 и на mem.swapio out > 1MB/s в течение 5 минут. Теперь такую деградацию видно заранее.
Быстрый старт: минимальная безопасная установка
Если вы прямо сейчас пробуете на одном сервере, вот мой путь.
1. Установить агент. Официальный установочный скрипт сам определит дистрибутив и настроит запуск Netdata через systemd.
# установка одной строкой (Linux)
wget -O /tmp/netdata-kickstart.sh https://get.netdata.cloud/kickstart.sh
sh /tmp/netdata-kickstart.sh --stable-channel --disable-telemetry2. Закрыть доступ к дашборду. По умолчанию дашборд Netdata на порту 19999 доступен без логина и пароля. Если этот порт открыт, метрики сможет посмотреть любой, кто знает адрес сервера. Поэтому я привязываю Netdata к localhost и проксирую доступ через nginx с basic auth.
[web]
bind to = 127.0.0.1Ставим утилиту htpasswd и заводим пользователя (например, stats):
sudo apt install apache2-utils
sudo htpasswd -c /etc/nginx/.htpasswd statsДобавляем в конфиг nginx новый location, который проксирует на локальный Netdata и требует basic auth:
location /netdata/ {
proxy_pass http://127.0.0.1:19999/;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}Перезагружаем nginx — и дашборд доступен по https://your-domain/netdata/ за логином и паролем:
sudo systemctl reload nginx3. Уведомления в Telegram. Для одного человека Telegram удобнее остальных каналов: алерт прилетает мгновенно, видно прямо на залоченном экране, не теряется в почте. Настраивается за пару минут.
Сначала создаём бота: пишем @BotFather, отправляем /newbot, придумываем имя — в ответе будет токен вида 1234567890:AAA.... Свой chat ID берём через @userinfobot: достаточно отправить ему любое сообщение.
Дальше прописываем оба значения в конфиге уведомлений:
SEND_TELEGRAM="YES"
TELEGRAM_BOT_TOKEN="1234567890:AAA..."
DEFAULT_RECIPIENT_TELEGRAM="123456789"Отправляем тестовое сообщение, чтобы убедиться, что алерты доходят:
sudo netdatacli reload-health
sudo -u netdata /usr/libexec/netdata/plugins.d/alarm-notify.sh test4. Убрать лишний шум и нагрузку. Netdata из коробки показывает много метрик, но не все они нужны каждый день. Я отключаю лишние плагины и настраиваю пороги алертов под свою инфраструктуру, чтобы уведомления не засирали чатик с алертами.
Например, отключаю то, что мне точно не пригодится:
[plugins]
# Очень прожорливый, нужен только для deep kernel tracing
ebpf = no
# Low-level профилирование CPU
perf = no
# Читает логи, лишняя нагрузка
systemd-journal = no
# OpenTelemetry не нужен (уже есть Sentry)
otel = no
otel-signal-viewer = no
network-viewer = no
# Низкоуровневые метрики ядра, почти никогда не нужны
nfacct = no
slabinfo = no
debugfs = noКак смотреть метрики всех серверов в одном месте
На одном сервере Netdata agent сам собирает метрики, хранит их локально и показывает дашборд. Это удобно, пока сервер один. Но когда появляется несколько VPS (или БД с каким-нибудь Memcached), заходить на каждый сервер отдельно становится неудобно.
Для этого у Netdata есть схема с одним parent-сервером и несколькими child-агентами. Child-серверы собирают свои локальные метрики и отправляют их на parent. Parent принимает эти потоки, хранит историю централизованно и позволяет смотреть состояние всей инфраструктуры в одном месте.
┌──────────────────────────┐
│ vps-01 │
│ Netdata parent │
│ 30d retention │
│ alerts → Telegram │
└──────────▲───────────────┘
│
┌───────────────┴────────────────┐
│ │
stream collect metrics
│ │
┌───────────┼───────────┐ ┌─────────┴─────────┐
│ │ │ │ │
┌────▲────┐ │ ┌────▲────┐ ┌───▼──────────┐ ┌──────▼──────────┐
│ vps-02 │ ... │ vps-05 │ │ MySQL │ │ ClickHouse │
│ child │ │ child │ │ cluster │ │ cluster │
└─────────┘ └─────────┘ └──────────────┘ └─────────────────┘
На parent в /etc/netdata/stream.conf для каждого разрешённого child объявляется секция с UUID — он же служит API key:
[788df748-08ef-4f6b-be56-78247dec3ac5]
enabled = yes
default history = 21600
[9edcf9b2-cb5b-4654-b5c0-78acacbad8cd]
enabled = yes
default history = 21600default history = 21600 не имеет отношения к "30d retention" из схемы выше - это буфер на parent для каждого child (21600 секунд ~ 6 часов), чтобы метрики не терялись при коротких разрывах соединения. Настройки долговременного хранения метрик задаются в секции [db] у netdata.conf на parent.
Один UUID можно переиспользовать на нескольких children, а можно завести по отдельному ключу на каждый child — это позволяет задать разные настройки (например, время хранения метрик) для разных хостов.
На child нужно положить свой stream.conf в /etc/netdata/ (дефолтный шаблон лежит в /usr/lib/netdata/conf.d/stream.conf, копирую оттуда и правлю):
[stream]
enabled = yes
destination = stats.gistrec.cloud:19999
api key = 788df748-08ef-4f6b-be56-78247dec3ac5После рестарта обоих агентов child начинает стримить метрики, и они появляются в дашборде parent. Алерты крутятся только на parent. Удобно: пороги правлю в одном месте.
Когда parent–child не нужен: если у вас один сервер или маленький кластер, где достаточно встроенного дашборда на каждом агенте. Оверхед небольшой, но не нулевой: parent — это ещё один компонент, за которым нужно следить.
Метрики удалённых сервисов
Parent-сервер не обязательно получает метрики только от child-агентов. Он также может запускать collectors, которые подключаются к удалённым сервисам по сети и забирают метрики напрямую.
Это удобно для managed-сервисов и отдельных кластеров, где агент Netdata не установлен: MySQL, ClickHouse, Redis и других сервисов, доступных по сети.
В моей инфраструктуре Netdata parent собирает метрики с MySQL и ClickHouse кластеров. Для каждого сервиса настраивается отдельный collector: указываются host, port и учётные данные, после чего метрики отображаются в общем дашборде вместе с метриками child-серверов.
Например, для одного из моих ClickHouse кластеров конфиг выглядит так:
jobs:
- name: clickhouse_projects
url: https://projects.clickhouse.gistrec.cloud:8443
username: ...
password: ...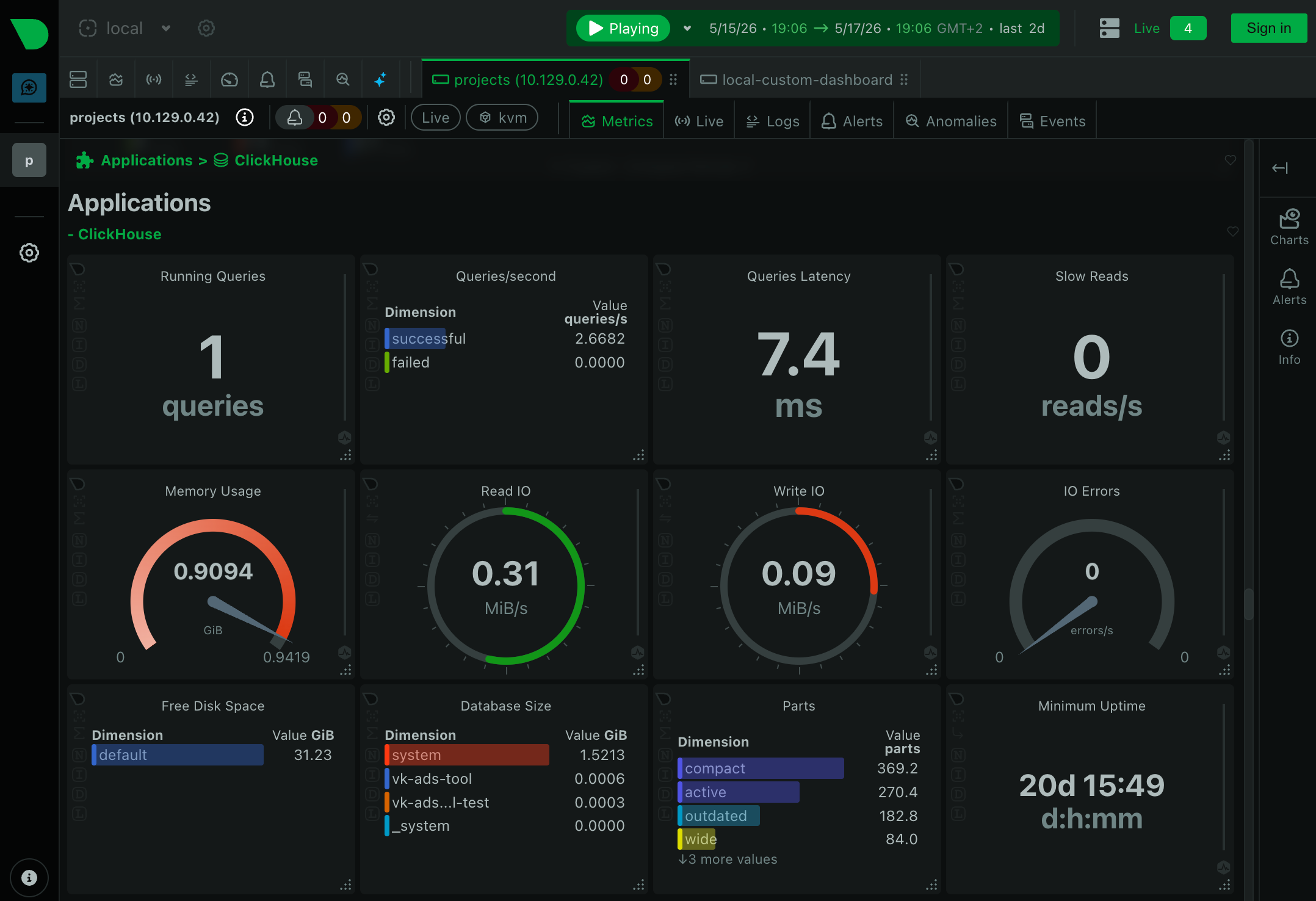
Плюс Netdata умеет собирать метрики не только с хостов, но и с сервисов: MySQL, PostgreSQL, Redis, ClickHouse, MongoDB, RabbitMQ, Elasticsearch, nginx, HAProxy и десятки других. Метрики и базовые алерты — из коробки, без отдельного exporter-процесса.
Грабли, на которые важно не наступить:
- Порт
19999по умолчанию открыт. Все данные доступны без логина и пароля, поэтому порт точно не стоит открывать наружу. - Использовать все дефолтные алерты. Netdata из коробки включает много базовых проверок, но не все они одинаково важны для конкретной инфраструктуры. Я отключил сбор лишних метрик (пример в конфиге выше) и подобрал пороги так, чтобы уведомления не были шумными.
- Реагировать на каждый warning как на инцидент. Варнинг не значит, что что-то сломалось. Но это сигнал, что скоро что-то может сломаться. Поэтому мьютить варнинги всё-таки не стоит.
- Забить на регулярный просмотр дашбордов. Раз в день полезно открыть дашборд и быстро проверить основные метрики. Раз в неделю — посмотреть историю алертов и подкрутить пороги для всего, где было false-positive срабатывание.
Если у вас есть Linux-серверы, но нет понятного мониторинга, смело начинайте с одного сервера. Поставьте Netdata, посмотрите на все доступные метрики. Часто уже за первые десять минут становится видно то, что раньше оставалось незаметным.